LiDAR classification assigns category labels to individual points — ground, vegetation, building, water, power line, or other features. Classification transforms raw point clouds into semantically meaningful data.

Why Classification Matters
Without classification, a point cloud is simply millions of XYZ coordinates. With classification, it becomes an organized dataset where you can:
- Isolate ground points for terrain modeling
- Extract buildings for urban mapping
- Identify vegetation for forestry analysis
- Map power lines for utility inspection
Classification information is stored within LAS/LAZ files as an integer attribute following ASPRS standards.
ASPRS Standard Classification Codes
Basic Classes
- 0 — Never Classified
- 1 — Unclassified
- 2 — Ground
- 7 — Low Point (Noise)
- 9 — Water
Vegetation
- 3 — Low Veg (0-0.5m)
- 4 — Medium Veg (0.5-2m)
- 5 — High Veg (>2m)
- 6 — Building
Infrastructure
- 10 — Rail
- 11 — Road Surface
- 14 — Wire Conductor
- 15 — Transmission Tower
- 17 — Bridge Deck
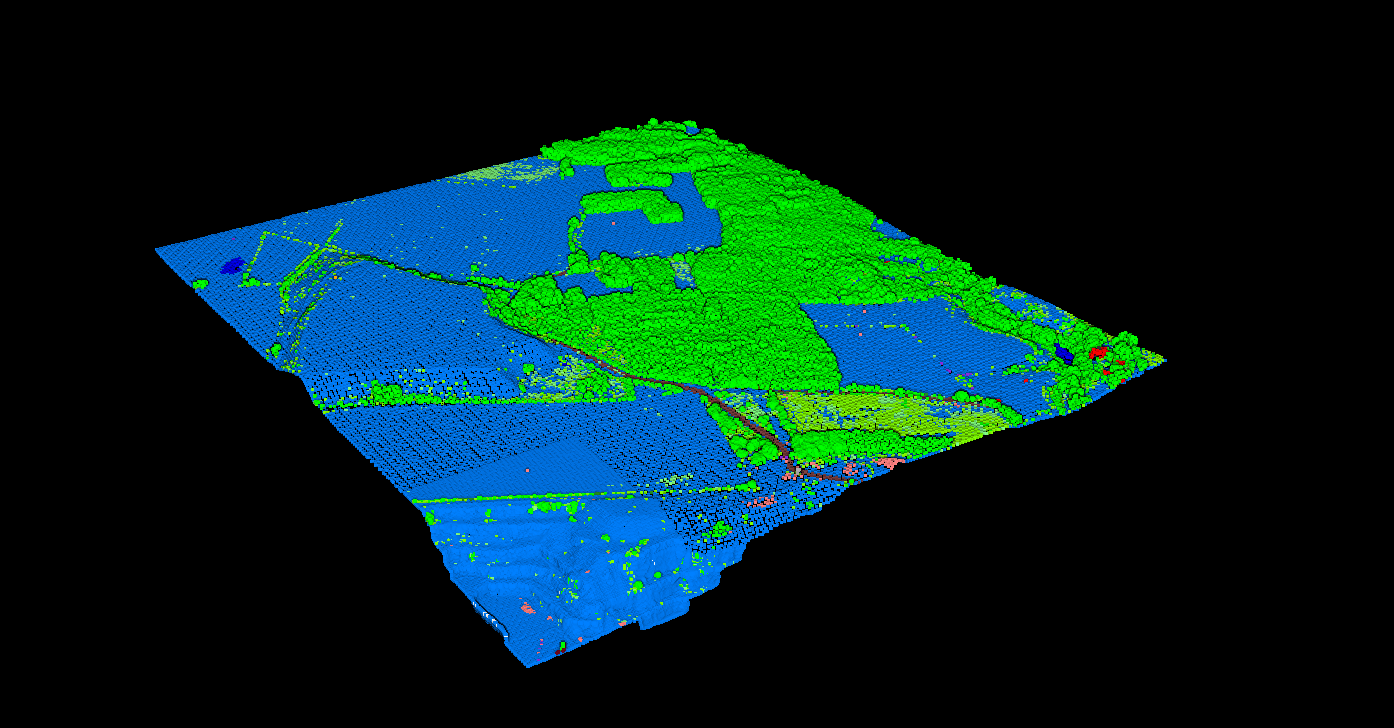
Classification in Agricultural Areas
In agricultural landscapes, classification separates cropland, hedgerows, farm buildings, and irrigation infrastructure. This enables precision farming analysis and land management planning.
The Classification Workflow
Step 1: Noise Classification
Always classify noise first. Outlier points corrupt subsequent algorithms — high noise (birds, atmosphere), low noise (multipath errors).
Step 2: Ground Classification
Ground classification is foundational. Building and vegetation classification require knowing where the ground is. Common algorithms: Progressive TIN Densification, Cloth Simulation Filter (CSF), SMRF.
Step 3: Building Classification
Algorithms identify buildings based on height above ground, planar surfaces, and geometric regularity.
Step 4: Vegetation Stratification
Separate points into height strata: Low (0-0.5m), Medium (0.5-2m), High (>2m). Distinguishing vegetation from buildings relies on scattered patterns vs planar surfaces.
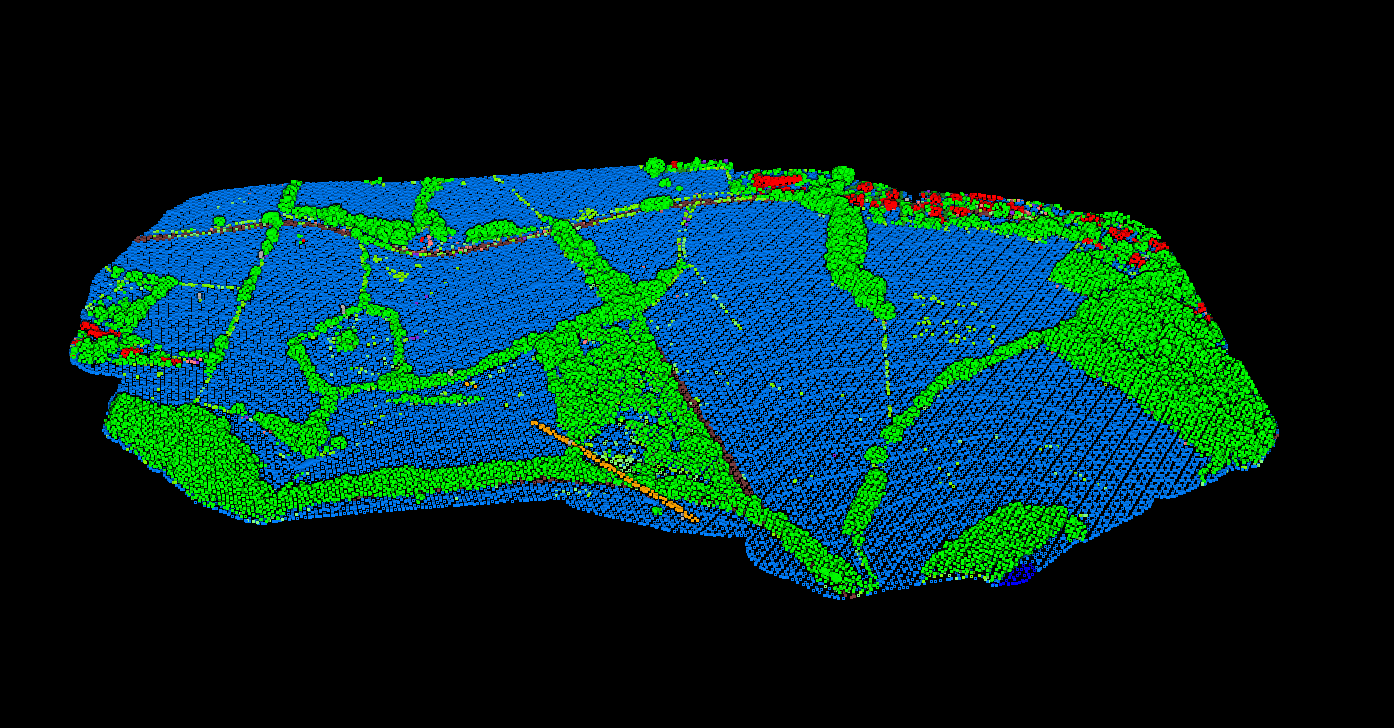
Rural & Forested Terrain
Classifying rural areas with mixed forest coverage requires careful parameter tuning. Ground classification algorithms must handle the transition between open fields and dense canopy, while vegetation stratification reveals the forest structure from understory to crown.
Ground Classification Algorithms
Power Line & Utility Classification
Power lines and transmission infrastructure require specialized classification algorithms. The thin linear geometry of conductors demands high point density and careful separation from surrounding vegetation. Classified power line data enables encroachment analysis and maintenance planning.
